Some email problems are unique and require customized solutions. While other issues are more widespread and plague our senders on a frequent basis. For these common problems, we’ve been increasingly applying machine learning solutions to optimize our customers’ email sends.
As a branch of artificial intelligence, machine learning
gives computers the ability to learn, and then continuously analyze and make predictions based on the input data. The immense scale of our platform—50 billion emails sent per month to billions of email addresses around the world—creates the ideal dataset with which to train our models. In this post, we'll dig into how we use machine learning to make our new
Email Validation API smarter.
Unfortunately,
8.4% of email addresses entered online are invalid, misspelled, or fake.
Inbox providers monitor your engagement with recipients. If you are continuously sending to invalid email addresses, they assume your emails are unwanted. Inbox providers will penalize you and filter more of your emails to spam, hurting your reputation and deliverability. Conversely, when you send to valid email addresses, mailbox providers reward you with better inbox placement.
Current in-house and third-party email address validation solutions have had limitations. We’ve often heard from customers expressing frustrations when trying to validate email addresses. They spend hours writing regular expressions to spot bad syntax in email addresses–only to have limited functionality. And precious dollars were thrown to third-party services without accessible sending integration.
We decided there had to be a smarter way.
In August at our
SIGNAL conference in San Francisco, we announced the open beta launch of our Email Validation API, and on
October 1, it became publicly available.
This real-time API detects invalid email addresses, like those that are mistyped, inactive, non-existent, disposable, or shared. We do this by leveraging our massive scale, and harnessing the power of machine learning.
Our research showed that machine learning is the most accurate, secure, and reliable method to validate email addresses. No need to waste development hours writing long, ugly regular expressions that only check syntax errors.
Easily avoid spammer tactics (such as the
broken SMTP handshake) that mailbox providers frown upon. Machine learning automatically learns patterns in the data, without us needing to think of and hard code every possible variation. This leads to our end goal of decreasing
hard bounce rates, improving reputation with inbox providers, and increasing overall deliverability.
Our Data Science team used a neural network model to classify invalid and valid emails. They applied a convolutional neural network (CNN) and recurrent neural network (RNN) layers to capture and remember patterns in the email address.
CNNs are traditionally used in image processing, but were used here to create
n-gram data of character sequences which are fed to an RNN. The RNN is able to learn the patterns of these character sequences which it uses to distinguish valid email addresses from invalid ones.
This approach allowed us to learn more complex patterns and make specific predictions as the data changes.
We decided that we specifically wanted to predict the following factors, as they are the primary drivers of email address validity:
- Email address syntax: Does the email address have proper syntax, including a recipient name, @ symbol, domain name, and top-level domain (such as .com, .edu, .org)?
- MX and/or A record: Does the mail server and domain exist and will the server accept email communication?
- Role email addresses: Is the email address used by several people at a company who have a shared role, like “sales@example.com”?
- Disposable email addresses: Is this a temporary email address that the user will not engage with and throw away?
- Keyboard smashes: Did a user knowingly or unknowingly input a random and unintelligible string of characters as an email address?
- Suspected and known hard bounces: Is this an email address that has been known to bounce in the past or is highly suspect to bounce based on previous sending?

Each individual email address is converted to a matrix. The matrix is put into the neural network where the model can capture the order of the characters. In contrast to the traditional "rules-based’"approach, a neural network model can detect patterns that wouldn’t occur to us as humans due to our own biases.
Next, the model aggregates the predictions that it made from each feature and produces the probability that an email address is invalid, using a risk score of 0-100%. Classification then distinguishes between the scores and determines the corresponding verdict of Valid, Risky, or Invalid.
You can integrate the
Email Validation API with your sign-up form, and use the power of machine learning to make informed decisions on which addresses to keep and which to remove. All of the information and transparent reasons for the score are easily accessible in the Twilio SendGrid UI.
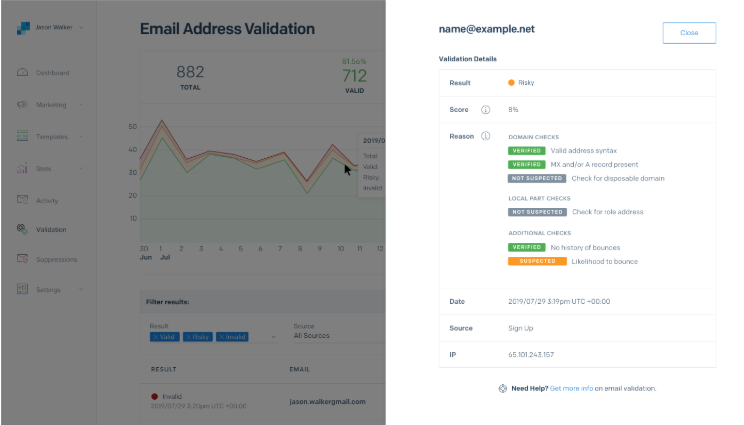
All Email API customers on Pro and Premier plans can integrate machine learning into sending practices with the Email Validation API!
Create an API Key in your Twilio SendGrid dashboard and check out our
documentation to try the tool for free.