Send With Confidence
Partner with the email service trusted by developers and marketers for time-savings, scalability, and delivery expertise.

Time to read: 22 minutes
Note: This is a post from #frontend@twiliosendgrid. For other engineering posts, head over to the technical blog roll.
As SendGrid’s frontend architecture started to mature across our web applications, we wanted to add another level of testing in addition to our usual unit and integration test layer. We sought to build new pages and features with E2E (end-to-end) test coverage with browser automation tools.
We desired to automate testing from a customer’s perspective and to avoid manual regression tests where possible for any big changes that may occur to any part of the stack. We had, and still have, the following goal: provide a way to write consistent, debuggable, maintainable, and valuable E2E automation tests for our frontend applications and integrate with CICD (continuous integration and continuous deployment).
We experimented with multiple technical approaches until we finalized on our ideal solution for E2E testing. On a high-level, this sums up our journey:
This blog post is one of two parts documenting and highlighting our experiences, lessons learned, and tradeoffs with each of the approaches used along the way to hopefully guide you and other developers into how to hook up E2E tests with helpful patterns and testing strategies.
Part one encompasses our early struggles with STUI, how we migrated to WebdriverIO, and yet still experienced a lot of similar downfalls to STUI. We will go over how we wrote tests with WebdriverIO, Dockerized the tests to run in a container, and eventually integrated the tests with Buildkite, our CICD provider.
If you would like to skip ahead to where we are at with E2E testing today, please go on ahead to part two as it goes through our final migration from STUI and WebdriverIO to Cypress and how we set it up across different teams.
TLDR: We experienced similar pains and struggles with both Selenium wrapper solutions, STUI and WebdriverIO, that we eventually started to look for alternatives in Cypress. We learned a bunch of insightful lessons to tackle writing E2E tests and integrating with Docker and Buildkite.
When initially seeking out a browser automation tool, our SDETs (software development engineers in test) dove into making our own custom in-house solution built with Ruby and Selenium, specifically Rspec and a custom Selenium framework called Gridium. We valued its cross-browser support, ability to configure our own custom integrations with TestRail for our QA (Quality Assurance) engineer test cases, and the thought of building the ideal repo for all frontend teams to write E2E tests in one location and to be run on a schedule.
As a frontend developer eager to write some E2E tests for the first time with the tools the SDETs built for us, we started to implement tests for the pages we already released and pondered how to properly set up users and seed data to focus on parts of the feature we wanted to test. We learned some great things along the way like forming page objects for organizing helper functionality and selectors of elements we wish to interact with by page and started to form specs that followed this structure:


deepmerge to handle it for us, but it is important to note that merging is not always perfect with nested objects or arrays. Always double check the resulting output configs as it may lead to undefined behavior when there are duplicate properties that did not merge correctly.
wdio.conf.js, like this:
wdio.localhost.conf.js, by the following:
wdio.staging.conf.js, similar to this:
wdio.cicd.testing.conf.js and wdio.cicd.staging.conf.js, like so:
package.json script commands that would serve as the foundation for our testing. For this example, we prefixed the commands with “uitest” to denote UI tests with WebdriverIO and because we also ended test files with *.uitest.js. Here are some sample commands for the staging environment:
Page class and adding the selectors to certain elements we wished to interact with or assert upon and helper functions to perform actions on the page.
super.open(...) with the page’s specific route so we can visit the page with this call, SomePage.open(). We also exported the class already initialized so we can reference the elements like SomePage.submitButton or SomePage.tableRows and interact with or assert upon those elements with WebdriverIO commands. If the page object was meant to be shared and initialized with its own member properties in a constructor, we could also export the class directly and instantiate the page object in the test files with new SomePage(...constructorArgs).
login helper function that takes in a username and password that makes the same API call we use for our login page and which eventually returns back our auth token needed to stay logged in and to pass along the headers of protected API requests. Other companies may have even more custom internal endpoints or tools to create brand new users with seed data and configurations quickly, but we, unfortunately, did not have one fleshed out enough. We would do it the old-fashioned way and create dedicated test users in our environments with different configurations through the UI and often broke up tests for pages with distinct users to avoid clashing of resources and remain isolated when tests ran in parallel. We had to make sure the dedicated test users were not touched by others or else the tests would break when someone unknowingly tinkered with one of them.Dockerfiles and docker-compose.yml files and plenty of experimentation with spinning up Docker containers locally to get things working.
selenium-hub service in the docker-compose file.selenium-chrome service in the docker-compose.yml file.Dockerfile to provide an environment with Node to install npm packages and run package.json scripts, copy over the test code, and assign a service dedicated to running the test files named uitests in the docker-compose.yml file.Dockerfile called Dockerfile.uitests and installed all the node_modules and copied the code over to the image’s working directory in a Node environment. This would be used by our uitests Docker Compose service and we achieved the Dockerfile setup in the following way:
selenium-hub, selenium-chrome, and uitests services in the docker-compose.uitests.yml file:
depends_on, and exposing ports to services. Our test application code image would eventually be pushed up and pulled from a private Docker registry we manage.
VERSION and PIPELINE_SUFFIX to reference the images by a tag and more specific name. We would then start up the Selenium services and execute commands through the uitests service to execute the WebdriverIO tests.
docker-compose up and docker-compose down with the Mac Docker installed on our machines to locally test our images had the proper configurations and ran smoothly before integrating with Buildkite. We documented all the commands needed to construct the tagged images, push them up to the registry, pull them down, and run the tests according to environment variable values.
.yml file on our AWS machines with Bash scripts and environment variables set either through the code or the Buildkite settings UI for our repo’s pipeline.
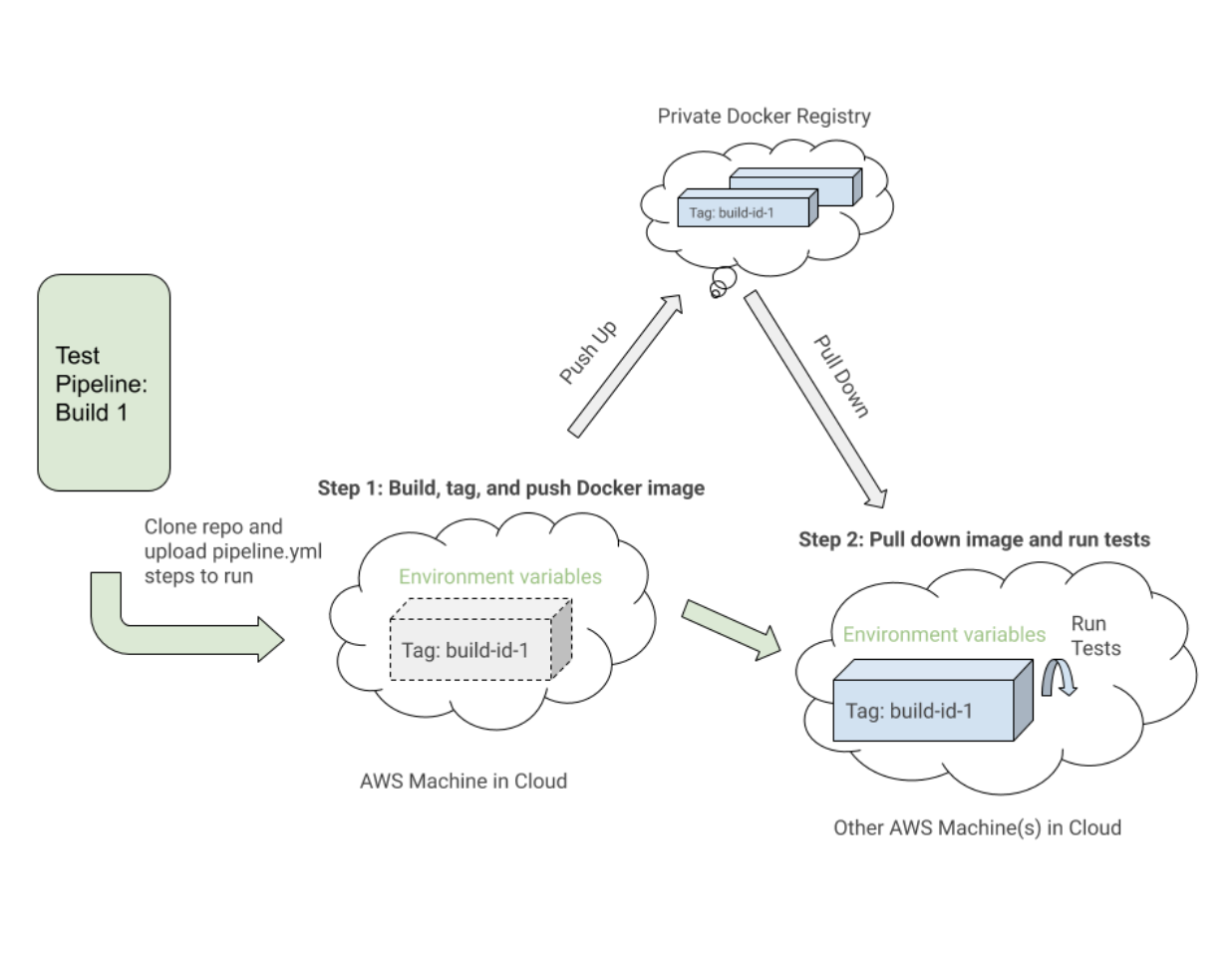
pipeline.uitests.yml file that demonstrates setting up the Docker images in the “Build UITests Docker Image” step and running the tests in the “Run Webdriver tests against Chrome” step:
build command to build the uitests service with all of the application test code and tagged it with latest and ${VERSION} environment variable so we can eventually pull down that same image with the proper tag for this build in a future step.
$UITESTENV and $UITESTSUITE, we would pick and choose the type of command to run like npm run uitest: and the test suites to run for this specific Buildkite build such as --suite $UITESTSUITE.
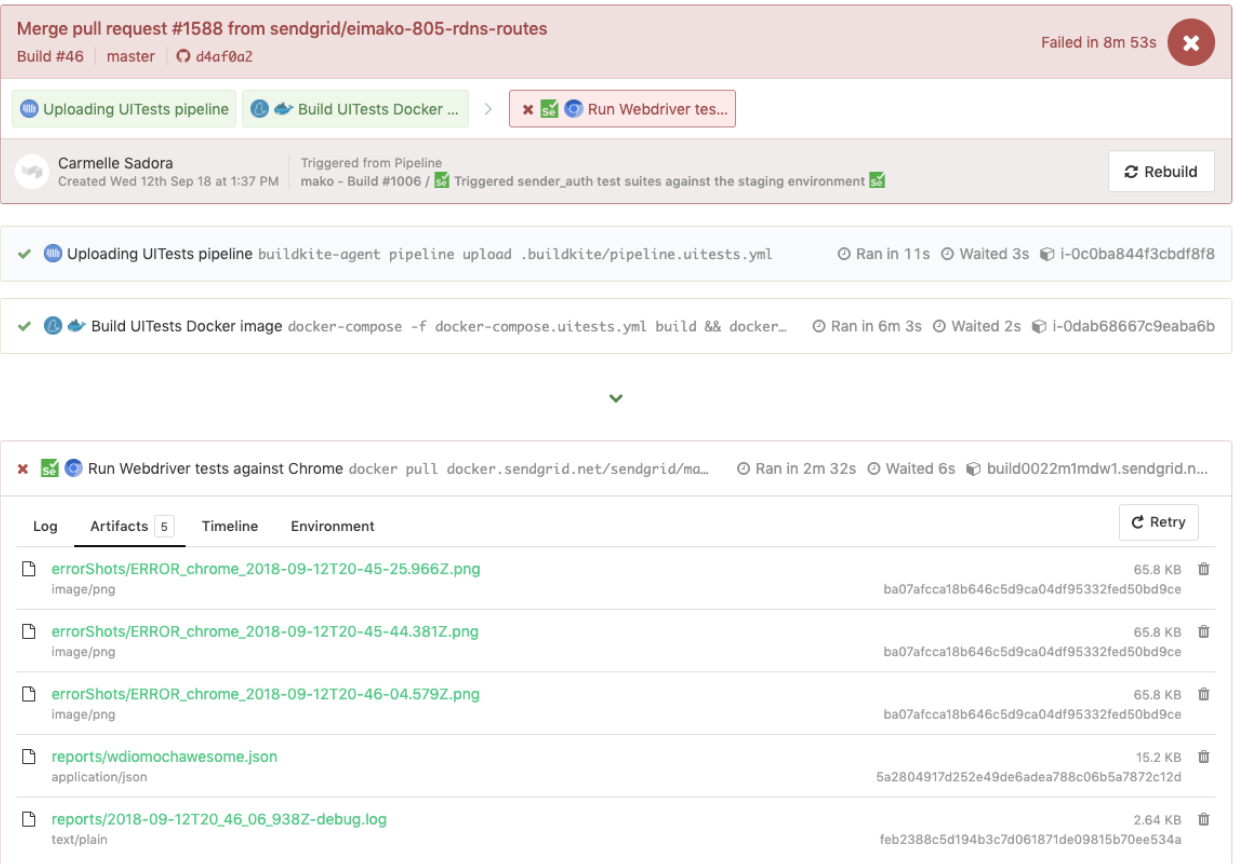
pipeline.uitests.yml file but with environment variables set where the pipeline was triggered. This build failed and had error screenshots for us to take a look at under the Artifacts tab and the console output under the Logs tab. Remember the artifact_paths in the pipeline.uitests.yml (https://gist.github.com/alfredlucero/71032a82f3a72cb2128361c08edbcff2#file-pipeline-uitests-yml-L38), screenshots settings for `mochawesome` in the `wdio.conf.js` file (https://gist.github.com/alfredlucero/4ee280be0e0674048974520b79dc993a#file-wdio-conf-js-L39), and mounting of the volumes in the `uitests` service in the `docker-compose.uitests.yml` (https://gist.github.com/alfredlucero/d2df4533a4a49d5b2f2c4a0eb5590ff8#file-docker-compose-yml-L32)?
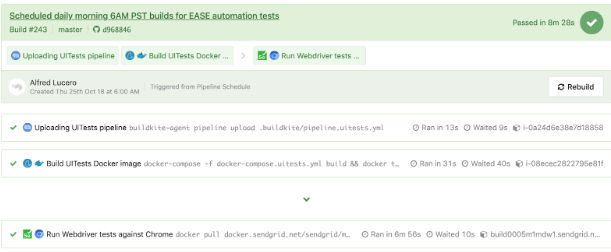
pipeline.uitests.yml file except with environment variables already configured in the Buildkite pipeline settings is displayed underneath.
.yml files with specific syntax, GUI settings, Bash scripts, or any other means.
$ vs. $$ for singular vs. plural elements, $(‘...’).waitForVisible(9000, true) for waiting for an element to not be visible, and other unintuitive commands. We experienced a lot of flaky selectors and had to explicitly $(...).waitForVisible() for everything.browser.debug() but it often did not work or did not provide enough information. We gradually gathered a bunch of console error messages and mapped them to possible solutions over time but it took lots of pain and headache to get there.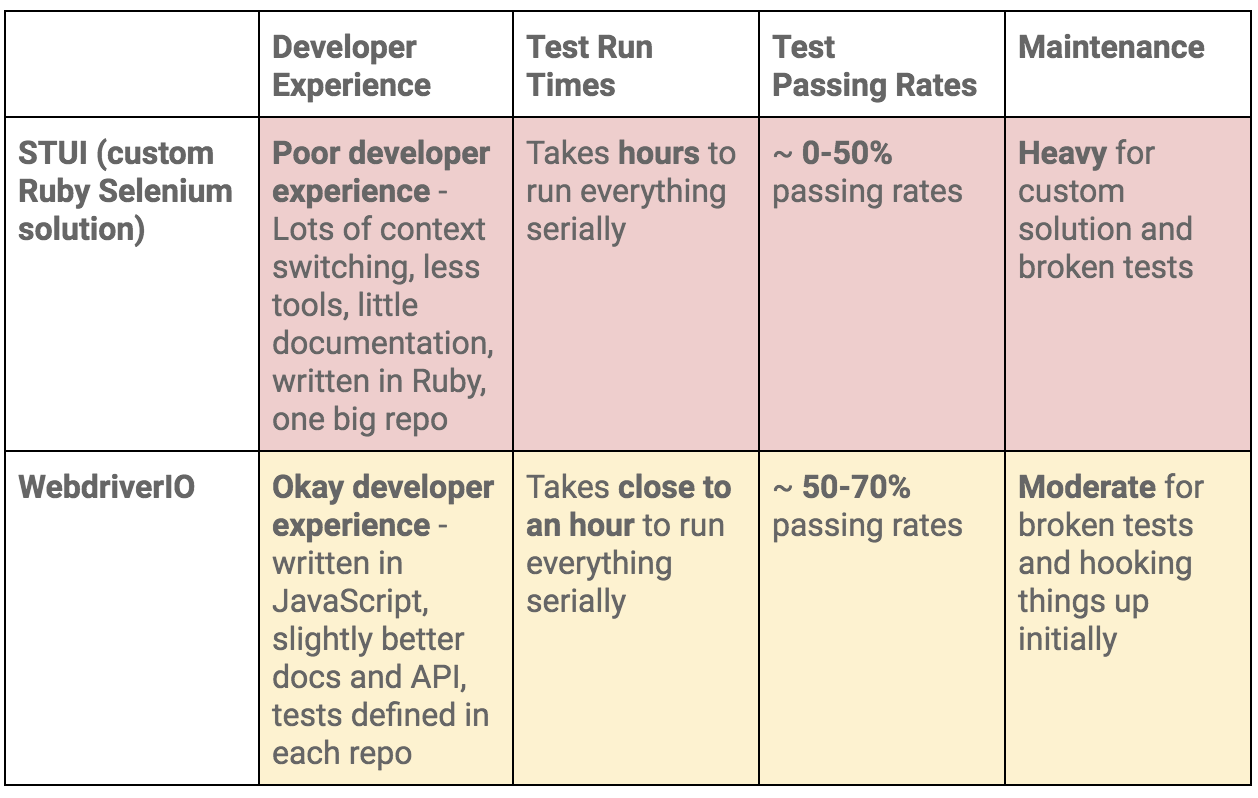
Partner with the email service trusted by developers and marketers for time-savings, scalability, and delivery expertise.